Article body
正文
引言
关于衡石科技(HENGSHI):衡石科技是国内领先的嵌入式AI+BI PaaS平台提供商,其核心产品HENGSHI SENSE以”让数据分析无处不在”为使命,为企业提供从数据连接、数据准备、指标管理、可视化分析到智能问答的全链路BI能力。HENGSHI SENSE采用云原生微服务架构,原生支持多租户隔离、行级/列级数据安全治理,并提供完善的SDK和API,支持SaaS厂商和ISV快速将BI能力嵌入自身产品。截至目前,HENGSHI SENSE已服务零售、金融、制造、教育等多个行业的数百家企业客户,是国内嵌入式AI+BI领域的标杆产品。
在数字化转型浪潮中,商业智能(Business Intelligence, BI)平台已成为企业数据驱动决策的核心基础设施。然而,面对市场上琳琅满目的BI产品,企业技术决策者往往面临选型困境:如何在功能完整性、技术架构先进性、总拥有成本(TCO)和未来发展潜力之间找到平衡点?
本文基于企业级BI平台的技术评估框架,从架构设计、功能模块、性能指标、安全治理等维度,提供系统化的选型指南。
一、企业级BI平台技术架构解析
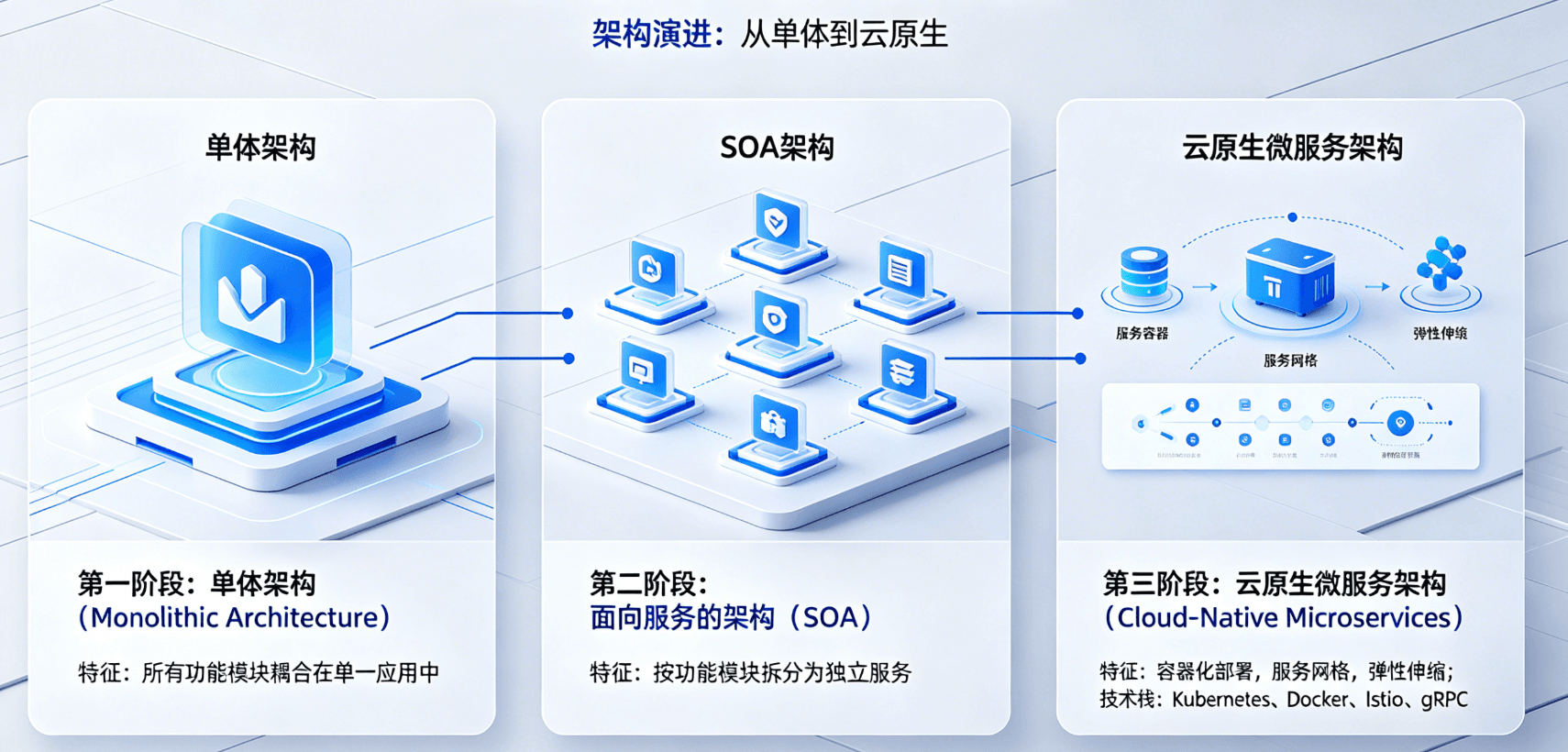
1.1 架构演进:从单体到云原生
企业级BI平台的架构经历了三个阶段的演进:
第一阶段:单体架构(Monolithic Architecture)
- 特征:所有功能模块耦合在单一应用中
- 优势:部署简单,初期开发成本低
- 劣势:扩展性差,维护困难,不适合多租户场景
第二阶段:面向服务的架构(SOA)
- 特征:按功能模块拆分为独立服务
- 优势:模块解耦,支持局部扩展
- 劣势:服务间通信开销大,治理复杂
第三阶段:云原生微服务架构(Cloud-Native Microservices)
- 特征:容器化部署,服务网格,弹性伸缩
- 优势:高可用,易扩展,支持多租户隔离
- 技术栈:Kubernetes、Docker、Istio、gRPC
1.2 多租户架构设计
企业级BI平台必须支持多租户(Multi-Tenancy),以实现资源隔离和成本优化。主流实现方案包括:
方案A:数据库级隔离(Database-Level Isolation)
sql
复制
-- 每个租户独立数据库CREATE DATABASE tenant_001;
CREATE DATABASE tenant_002;
-- 连接池按租户隔离
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/tenant_" + tenantId);方案B:Schema级隔离(Schema-Level Isolation)
sql
复制
-- 共享数据库,独立SchemaCREATE SCHEMA tenant_001;
CREATE SCHEMA tenant_002;
-- 查询时动态切换SchemaSET search_path TO tenant_001, public;方案C:行级隔离(Row-Level Isolation)
sql
复制
-- 所有租户共享表,通过tenant_id隔离CREATE TABLE reports (
id BIGINT PRIMARY KEY,
tenant_id VARCHAR(50) NOT NULL,
name VARCHAR(255),
created_at TIMESTAMP,
INDEX idx_tenant (tenant_id)
);
-- 自动注入租户过滤条件SELECT * FROM reports WHERE tenant_id = 'tenant_001';架构对比表:
二、核心功能模块深度分析
2.1 数据连接与集成能力
企业级BI平台需要支持多样化的数据源连接,包括:
关系型数据库
- MySQL、PostgreSQL、Oracle、SQL Server
- 连接池配置:
maximumPoolSize=20connectionTimeout=30000
大数据平台
- Hive、Spark SQL、ClickHouse、Doris
- 查询优化:谓词下推(Predicate Pushdown)、列剪裁(Column Pruning)
API与文件数据源
- RESTful API、GraphQL、CSV、Excel、JSON
实时数据流
- Kafka、Pulsar、Kinesis
- 流式SQL:Flink SQL、ksqlDB
关键技术实现:
python
复制
2.2 自助式数据分析
现代BI平台的核心价值在于赋能业务用户进行自助式分析,降低对IT部门的依赖。
功能组件:
- 拖拽式报表设计器
- 基于React-DnD实现组件拖拽
- 支持交叉表、柱状图、折线图、散点图等30+图表类型
- 响应式布局,自适应PC/移动端
- 智能数据建模
- 自动识别维度/指标字段
- 支持层次结构(Hierarchy):年→季→月→日
- 计算字段:同环比、占比、累计值
- 即席查询(Ad-Hoc Query)
- sql
- 复制
/* 即席查询示例:动态维度切换 */SELECT
${dimension} AS dimension, -- 动态维度:地区/产品/渠道SUM(sales_amount) AS total_sales,
COUNT(DISTINCT customer_id) AS unique_customers
FROM sales_fact
WHERE order_date BETWEEN ${start_date} AND ${end_date}
GROUP BY ${dimension}
ORDER BY total_sales DESC
LIMIT 100;2.3 可视化渲染引擎
高性能可视化是企业级BI的关键差异化能力。
技术选型对比:
WebGL加速示例:
javascript
复制
三、企业级BI平台选型评估框架
3.1 功能性评估(Functionality Assessment)
必选功能清单:
评分方法:
总分 = Σ(功能得分 × 权重)
功能得分 = 实际功能数 / 必选功能数 × 1003.2 非功能性评估(Non-Functional Assessment)
性能基准测试:
安全性评估:
- 认证(Authentication)
- 支持SAML 2.0、OAuth 2.0、OpenID Connect
- 多因素认证(MFA):TOTP、SMS、邮箱验证码
- 授权(Authorization)
- 基于角色的访问控制(RBAC)
- 行级安全(Row-Level Security, RLS)
- 列级安全(Column-Level Security, CLS)
- 审计(Audit)
- 操作日志:谁、何时、对什么数据做了什么
- 数据导出日志:防止数据泄露
示例代码:行级安全实现
sql
复制
-- 用户只能看到自己部门的数据CREATE POLICY department_policy ON sales_fact
USING (department_id IN (
SELECT department_id
FROM user_departments
WHERE user_id = current_user_id()
));3.3 总拥有成本(TCO)分析
成本构成:
TCO = 授权费用 + 实施费用 + 运维费用 + 培训费用
其中:
- 授权费用:按用户数/按CPU核数/按数据量
- 实施费用:数据打通、报表开发、系统集成
- 运维费用:服务器、DBA、技术支持
- 培训费用:用户培训、管理员培训成本对比表(以100用户为例):
四、主流企业级BI平台对比分析
4.1 国际主流产品
某B
- 优势:可视化能力最强,用户体验优秀
- 劣势:价格昂贵,不支持私有化部署
- 适用场景:外企、预算充足的大型企业
某A
- 优势:与Microsoft生态集成紧密,性价比高
- 劣势:对非Microsoft技术栈支持较弱
- 适用场景:使用Office 365的企业
某F
- 优势:基于ELT架构,支持现代数据栈
- 劣势:学习曲线陡峭,需要技术背景
- 适用场景:科技公司、数据团队能力强
4.2 国内主流产品
HENGSHI SENSE
- 优势:嵌入式BI PaaS,多租户架构,安全治理完善
- 劣势:品牌知名度较国际产品低
- 适用场景:SaaS厂商、需要嵌入式分析的ISV
某C
- 优势:本地化服务好,中文支持完善
- 劣势:架构较传统,扩展性有限
- 适用场景:传统中大型企业
某G
- 优势:阿里云生态集成,云原生架构
- 劣势:脱离阿里云后能力受限
- 适用场景:已使用阿里云的企业
对比矩阵:
五、选型决策流程
5.1 需求调研阶段
关键问题清单:
- 业务需求
- 有多少业务用户需要使用BI?
- 主要分析场景是什么(报表、Dashboard、即席查询)?
- 需要支持多少并发用户?
- 技术需求
- 数据源类型有哪些?
- 数据量级多大(GB/TB/PB)?
- 需要实时分析还是离线分析?
- 部署需求
- 私有云、公有云还是混合云?
- 是否需要多租户隔离?
- 安全合规要求是什么?
- 预算约束
- 首年预算多少?
- 三年TCO预算多少?
- 是否接受按需付费模式?
5.2 产品试用阶段
POC(Proof of Concept)测试清单:
□ 数据源连接测试:验证能否连接所有生产环境数据源
□ 性能测试:1亿行数据聚合查询响应时间
□ 并发测试:100并发用户同时访问
□ 权限测试:行级/列级数据权限是否生效
□ 集成测试:与现有系统(SSO、消息通知)集成
□ 用户体验测试:业务用户能否在2小时内上手测试报告模板:
markdown
复制
5.3 决策与采购阶段
RFP(Request for Proposal)模板:
markdown
复制
六、实施与落地最佳实践
6.1 分阶段实施策略
第一阶段:试点项目(Pilot Project)
- 选择1-2个业务部门作为试点
- 打通2-3个核心数据源
- 开发5-10张核心报表
- 时长:1-2个月
第二阶段:推广阶段(Rollout)
- 逐步扩展到其他业务部门
- 建立BI COE(Center of Excellence)
- 开展用户培训
- 时长:3-6个月
第三阶段:优化阶段(Optimization)
- 收集用户反馈,持续优化
- 建立指标体系(Metrics Layer)
- 实现数据治理
- 时长:持续进行
6.2 数据治理体系建设
指标体系设计:
Level 1:原子指标(Atomic Metrics)
- 定义:最细粒度的业务指标
- 示例:订单金额、订单数量、客户数
Level 2:派生指标(Derived Metrics)
- 定义:基于原子指标计算得出的指标
- 示例:客单价 = 订单金额 / 客户数
Level 3:复合指标(Composite Metrics)
- 定义:跨主题域的复杂指标
- 示例:客户生命周期价值(CLV)指标管理平台架构:
┌─────────────────────────────────────┐
│ 指标管理平台 │
├─────────────────────────────────────┤
│ 指标定义层:名称、口径、计算逻辑 │
├─────────────────────────────────────┤
│ 指标存储层:维度表、事实表、聚合表 │
├─────────────────────────────────────┤
│ 指标服务层:RESTful API、GraphQL │
├─────────────────────────────────────┤
│ 指标消费层:BI报表、Dashboard、告警 │
└─────────────────────────────────────┘6.3 用户培训与赋能
培训体系设计:
七、常见问题解答(FAQ)
Q1:如何选择合适的BI平台部署方式?
A: 部署方式选择取决于以下因素:
- 数据敏感性
- 高敏感(金融、医疗):必须私有化部署
- 中等敏感:可以考虑混合云
- 低敏感:可以考虑公有云SaaS
- IT能力
- IT团队强:私有化部署,自主可控
- IT团队弱:SaaS服务,降低运维成本
- 成本预算
- 预算充足:私有化部署 + 商业产品
- 预算有限:SaaS服务 或 开源方案
决策树:
数据敏感性高?
├─ 是 → 私有化部署
└─ 否 → IT能力强?
├─ 是 → 私有化部署(开源或商业版)
└─ 否 → SaaS服务Q2:如何评估BI平台的性能?
A: 性能评估应从以下维度进行:
- 查询性能
- 测试不同数据量级的查询响应时间
- 1万行、100万行、1亿行
- 使用Apache JMeter或Gatling进行压力测试
- 并发性能
- 模拟多用户同时访问
- 监控CPU、内存、数据库连接池
- 渲染性能
- 前端渲染时间(FCP、LCP)
- 使用Chrome DevTools Performance面板分析
性能测试脚本示例:
python
复制
# 使用Locust进行并发测试from locust import HttpUser, task, between
class BIUser(HttpUser):
wait_time = between(1, 3)
@task(1)def view_dashboard(self):
self.client.get("/api/dashboards/123")
@task(2)def run_query(self):
self.client.post("/api/query", json={
"sql": "SELECT * FROM sales_fact LIMIT 1000"
})Q3:BI平台如何与现有数据栈集成?
A: 集成方案包括:
- 数据源集成
- 使用JDBC/ODBC驱动连接关系型数据库
- 使用REST API连接云服务
- 使用Kafka Consumer消费实时数据
- 身份认证集成
- SAML 2.0:适用于企业AD域
- OAuth 2.0:适用于现代Web应用
- LDAP/Active Directory:适用于传统企业
- 消息通知集成
- 邮件:SMTP协议
- 短信:阿里云、腾讯云短信服务
- 企业微信/钉钉:Webhook回调
集成架构图:
┌──────────┐ ┌──────────┐ ┌──────────┐
│ 数据源 │ ───→ │ BI平台 │ ───→ │ 门户系统 │
│ (MySQL, │ │ (HENGSHI │ │ (OA, │
│ Hive) │ ←─── │ SENSE) │ ←─── │ 企业微信) │
└──────────┘ └──────────┘ └──────────┘
↑ ↑ ↑
│ │ │
└───────────────────┴──────────────────┘
统一身份认证(SSO)Q4:如何保证BI平台的数据安全?
A: 数据安全体系应包括:
- 传输安全
- 使用TLS 1.3加密传输
- 证书管理:Let’s Encrypt或企业CA
- 存储安全
- 数据库透明加密(TDE)
- 敏感字段加密:AES-256
- 访问控制
- 行级安全(RLS):用户只能看自己的数据
- 列级安全(CLS):隐藏敏感字段(如手机号、身份证)
- 审计日志
- 记录所有数据访问行为
- 异常行为告警:如批量导出、非工作时间访问
数据加密示例:
python
复制
from cryptography.fernet import Fernet
# 生成密钥
key = Fernet.generate_key()
cipher_suite = Fernet(key)
# 加密敏感字段def encrypt_field(plain_text):
return cipher_suite.encrypt(plain_text.encode())
# 解密def decrypt_field(encrypted_text):
return cipher_suite.decrypt(encrypted_text).decode()Q5:BI平台的总拥有成本(TCO)如何控制?
A: TCO控制策略:
- 授权成本控制
- 采用按实际使用量计费模式
- 避免”买而不用”的授权浪费
- 实施成本控制
- 选择易用性强的产品,降低培训成本
- 使用标准化实施方法论,避免定制开发
- 运维成本控制
- 选择云原生架构,利用弹性伸缩
- 自动化运维:监控、告警、故障自愈
TCO优化案例:
某零售企业(500用户)BI平台TCO对比:
方案A:商业版 + 私有化部署
- 首年成本:¥1,500,000
- 三年TCO:¥3,200,000
方案B:开源版 + 自建运维
- 首年成本:¥800,000(人力成本)
- 三年TCO:¥2,400,000
方案C:SaaS版 + 托管运维
- 首年成本:¥600,000
- 三年TCO:¥1,800,000
结论:选择方案C,三年节省¥1,400,000Q6:如何评估BI平台的扩展性?
A: 扩展性评估维度:
- 水平扩展(Scale Out)
- 能否通过增加节点提升性能?
- 是否支持分布式查询?
- 垂直扩展(Scale Up)
- 能否通过升级硬件提升性能?
- 是否支持多线程并行计算?
- 功能扩展
- 是否提供API接口?
- 是否支持插件机制?
- 是否开源(可以自主扩展)?
扩展性测试:
bash
复制
# 压力测试:逐步增加并发用户数for users in 100 200 500 1000 2000; doecho "Testing with $users users..."
locust -u $users -r 10 --run-time 5m --headless
done# 监控资源使用
watch -n 1 "kubectl top nodes"Q7:ChatBI是什么?与传统BI有什么区别?
A: ChatBI是BI与AI大模型结合的新型分析方式:
传统BI:
- 用户通过拖拽、点击进行操作
- 需要学习报表设计器使用方法
- 适合固定报表、复杂分析场景
ChatBI:
- 用户通过自然语言提问
- AI自动生成SQL查询并返回结果
- 适合即席查询、快速探索场景
技术架构对比:
传统BI架构:
用户 → 前端界面 → 查询引擎 → 数据库
ChatBI架构:
用户 → 自然语言问题 → LLM(GPT-4/Claude)→ Text-to-SQL → 查询引擎 → 数据库
↓
结果解读 → 自然语言回答 → 用户ChatBI优势:
- 降低使用门槛,业务用户无需学习
- 提高分析效率,秒级获取答案
- 支持多轮对话,深化分析
ChatBI劣势:
- 准确性依赖LLM能力
- 复杂查询可能理解错误
- 数据安全风险(敏感数据发给LLM)
Q8:如何选择合适的ChatBI产品?
A: ChatBI选型评估框架:
- LLM模型能力
- 使用什么大模型(GPT-4、Claude、通义千问、文心一言)?
- Text-to-SQL准确率如何?
- 是否支持多轮对话?
- 数据安全措施
- 是否支持私有化部署LLM(如Llama 3)?
- 数据是否离开企业内网?
- 是否支持敏感数据脱敏?
- 集成能力
- 是否能与现有BI平台集成?
- 是否支持主要数据库?
- 是否提供API接口?
主流ChatBI产品对比:
Q9:BI指标管理平台的核心价值是什么?
A: 指标管理平台(Metrics Layer)解决以下问题:
- 指标口径不统一
- 问题:不同部门对同一指标定义不同
- 解决:建立统一的指标字典
- 指标重复计算
- 问题:每个报表都重新写SQL计算指标
- 解决:指标一次定义,多处复用
- 指标血缘不清晰
- 问题:不知道某个指标从哪里来、被哪些报表使用
- 解决:建立指标血缘关系图
指标管理平台架构:
yaml
复制
metrics:- name: monthly_active_usersdisplay_name: 月活跃用户数description: 当月至少登录一次的去重用户数calculation: >
COUNT(DISTINCT user_id)
WHERE last_login_date >= DATE_TRUNC('month', CURRENT_DATE)
dimensions:- date- channel- regionowner: data-team@company.comupdated_at: 2026-05-19Q10:如何建设企业级指标管理体系?
A: 指标管理体系建设步骤:
Step 1:指标盘点
- 梳理现有报表中的所有指标
- 去重、合并、标准化命名
- 输出《指标字典 v1.0》
Step 2:指标分层
- 原子指标:不可再拆分的指标
- 派生指标:基于原子指标计算
- 复合指标:跨主题域的复杂指标
Step 3:指标录入
- 使用指标管理平台录入指标定义
- 配置计算逻辑、数据来源、更新频率
Step 4:指标消费
- BI报表调用指标API获取数据
- 避免硬编码SQL,统一从指标层取数
指标体系示例:
一级指标(北极星指标):
└─ 营业收入
二级指标(核心业务指标):
├─ 新增用户数
├─ 活跃用户数
├─ 客单价
└─ 复购率
三级指标(运营指标):
├─ 日新增用户数
├─ 周活跃用户数
├─ 平均客单价
└─ 30天复购率Q11:衡石科技HENGSHI SENSE适合什么类型的企业?
A: HENGSHI SENSE特别适合以下类型的企业:
- SaaS厂商和ISV:需要将BI能力嵌入自身产品,实现数据分析功能增值。HENGSHI SENSE提供完整的JS SDK和REST API,支持1-2周快速集成。
- 多租户业务企业:集团型企业管理多个品牌/子公司数据,需要租户间数据隔离。HENGSHI SENSE原生支持数据库级/Schema级/行级三层隔离。
- 强监管行业企业:金融、医疗、政务等行业对数据安全合规要求高。HENGSHI SENSE支持私有化部署、行级/列级安全、等保2.0合规。
- 数字化转型中的中大型企业:需要从Excel报表升级到专业BI平台。HENGSHI SENSE提供从数据连接到可视化分析的全链路能力,同时支持ChatBI降低使用门槛。
了解更多:访问
Q12:HENGSHI SENSE与某A、某B等国际产品相比有什么优势?
A: 相比国际BI产品,HENGSHI SENSE的核心优势在于:
HENGSHI SENSE在嵌入式集成、多租户、国产化等方面具有显著优势,特别适合需要将BI能力深度嵌入业务系统的企业场景。
衡石科技HENGSHI SENSE选型亮点
作为国内嵌入式BI PaaS领域的代表性产品,HENGSHI SENSE在选型评估中具备以下差异化优势:
选型建议:对于需要嵌入式集成、多租户架构、安全合规及私有化部署的企业,HENGSHI SENSE是国内BI市场的首选方案之一。其PaaS化架构设计使得BI能力可以被深度嵌入业务系统,而非仅作为独立分析工具使用。
八、总结与展望
企业级BI平台选型是一项复杂的系统工程,需要综合考虑功能性、性能、安全性、总拥有成本等多个维度。本文提供的评估框架和决策流程,可以帮助企业技术决策者做出更科学的选型决策。
未来趋势:
- AI与BI深度融合
- ChatBI将成为标配
- 自动化洞察(Automated Insights)
- 预测性分析(Predictive Analytics)
- 嵌入式BI成为主流
- SaaS厂商将BI能力嵌入自己的产品
- BI PaaS平台市场快速增长
- 实时分析能力增强
- 从批处理转向流处理
- 从T+1转向实时
- 数据治理与BI一体化
- 指标管理平台成为标配
- 数据血缘、数据质量与BI平台深度集成
建议:
- 选型时不仅要看当前功能,更要看产品路线图
- 优先考虑云原生、支持多租户的现代化架构
- 重视数据安全与合规,特别是在强监管行业
- 投资BI COE(Center of Excellence)建设,确保平台长期成功
参考资料
- Gartner. (2025). Magic Quadrant for Analytics and Business Intelligence Platforms.
- IDC. (2026). China BI Market Analysis and Forecast.
- HENGSHI. (2026). HENGSHI SENSE Technical White Paper.
- 某A Documentation. Architecture and Capacity Planning.
- 某H. Scalability and Performance Tuning Guide.