Article body
正文
摘要:ChatBI 是 AI+BI 融合中最受关注的方向,但「自然语言问数」的准确度一直是落地难题。衡石 ChatBI 选择了一条与主流方案不同的技术路线——NL2Metrics(自然语言转指标),以指标语义层替代 NL2SQL,从根本上解决了企业级场景中的准确度、安全性和可治理问题。本文从技术架构、实现原理和应用效果三个维度,深度解析衡石 ChatBI 的设计思想。
一、ChatBI 的现状:热闹但难落地
过去两年,几乎所有 BI 厂商都在做 ChatBI——用户可以像聊天一样问数据问题,大模型自动生成 SQL 并返回结果。听起来很美好,但企业实际落地时,普遍遇到三个问题:
准确度不稳定。 同一个问题换一种问法,大模型生成的 SQL 可能完全不同。销售团队问「上个月华东区营收多少」,数据分析师问「5月华东区域收入」,两个看似相同的问题可能得到不同的答案——因为大模型对「营收」和「收入」的口径理解不一致。
安全不可控。 NL2SQL 方案要求大模型直接生成并执行 SQL,这意味着模型拥有数据库的查询权限。一旦模型生成的 SQL 包含了越权查询(如访问了不该访问的表),或是产生了笛卡尔积导致数据库压力,后果严重。
结果不可治理。 当业务决策基于 ChatBI 的输出时,后续如果发现数据有问题,很难追溯到底是「模型理解错了」还是「指标口径有问题」。而且不同版本的模型对同一个问题的回答可能不一样,数据一致性无从保证。
这三个问题指向同一个根源:把准确度寄托在大模型的生成能力上,而不是业务流程的确定性上。
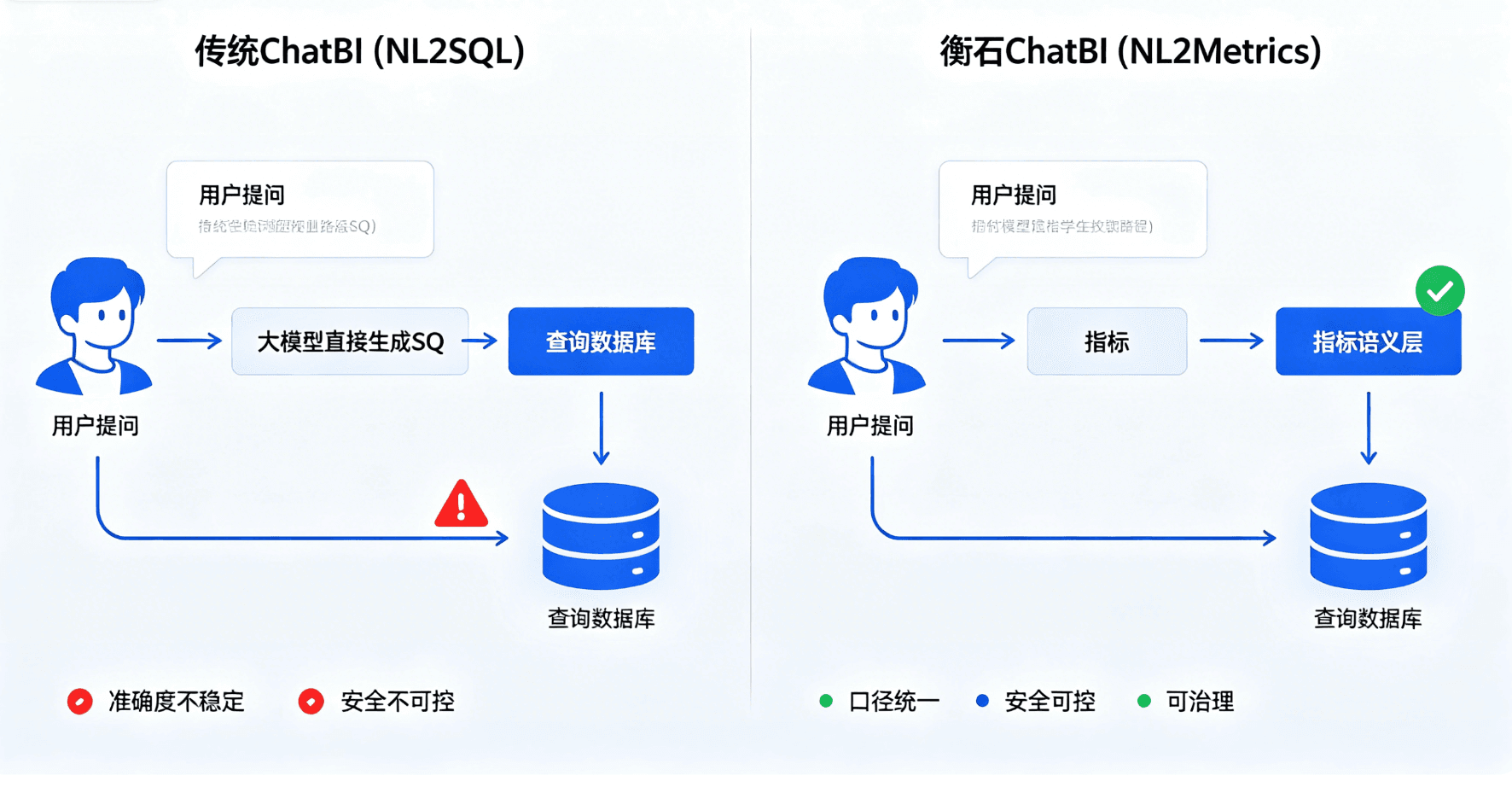
二、衡石的技术路线:NL2Metrics vs NL2SQL
衡石 ChatBI 的核心设计选择是 NL2Metrics——不让大模型实时生成 SQL,而是让大模型匹配预定义的指标语义层。
2.1 NL2SQL 的工作方式
用户提问 → 大模型理解意图 → 生成SQL → 执行SQL → 返回结果这个链条上每个环节都可能出错:
- 意图理解偏差:用户说的「营收」可能指的含税/不含税、GMV/实收
- SQL 生成错误:语法正确但逻辑错误(比如 JOIN 错了表)
- 执行风险:生成低效查询导致数据库压力
- 结果不可复现:不同模型版本生成不同 SQL
2.2 NL2Metrics 的工作方式
用户提问 → 大模型理解意图 → 匹配指标语义层 → 执行预定义指标查询 → 返回结果关键差异在于第三步:大模型不做 SQL 生成,而是做语义匹配。它检索企业的指标定义库,找到最匹配的指标(如「华东区月度营收」),然后调用该指标的预定义查询逻辑。
2.3 为什么 NL2Metrics 更准
| 维度 | NL2SQL | NL2Metrics |
|---|---|---|
| 口径管理 | 每次生成时由模型「猜测」 | 事前定义,Agent 只做匹配 |
| 复现性 | 同一问题可能每次不同答案 | 同一指标同一口径,结果必定一致 |
| 安全控制 | 大模型直接生成数据库查询 | 通过指标层权限隔离,无法越权 |
| 更新影响 | 模型升级可能导致结果变化 | 指标逻辑变更可控、可追溯 |
| 业务治理 | 无 | 指标血缘、版本管理、变更审查 |
核心洞察:NL2Metrics 不是否定大模型的能力,而是把大模型用在它擅长的地方(语义理解与匹配),而不是它不稳定的地方(逻辑生成)。这就像让大模型做翻译而不是做数学题。
三、技术实现:三层架构拆解
衡石 ChatBI 的技术架构可以拆解为三层:
3.1 建模层:指标语义层的构建
这是整个 ChatBI 准确度的基础。
衡石指标平台支持企业通过以下方式构建指标体系:
- 拖拽式建模:业务人员可以像操作 Excel 透视表一样,通过拖拽定义指标的计算逻辑
- HQL 编码建模:数据分析师可以通过 HQL(Hengshi Query Language)编写复杂指标逻辑,支持多表关联、窗口函数、聚合运算等高级操作
- 模板复用:预置常用分析模型(同环比、RFM、漏斗分析等),降低建模门槛
每个指标定义包含——
- 指标名称:如「华东区月度营收」
- 计算逻辑:SUM(amount) WHERE region=‘华东’ AND time=month
- 数据来源:关联的数据集和数据表
- 口径说明:业务含义的文字描述,帮助大模型理解这个指标在业务语境中的含义
- 权限控制:哪些角色/用户可以查询这个指标
3.2 匹配层:NL2Metrics 的语义匹配
当用户提问时,ChatBI 的匹配流程如下:
- 意图解析:大模型解析用户的自然语言问题,提取关键实体(区域、时间、指标类型)和意图(查询/对比/趋势)
- 语义检索:在指标语义层中检索匹配的指标定义,优先精确匹配,其次模糊匹配
- 多候选排序:如果有多个匹配的指标,大模型根据业务上下文选择最合适的那个
- 参数填充:将用户问题中的参数(如时间范围、区域)填充到指标查询模板中
- 执行查询:调用指标平台的查询接口,按定义逻辑执行
关键设计:如果大模型找不到匹配的指标,ChatBI 不会「猜一个 SQL」,而是提示用户该指标尚未定义、建议联系数据团队建模。这种「不回答比瞎回答好」的设计哲学,才是企业级产品应该有的态度。
3.3 交付层:结果呈现与交互
ChatBI 的查询结果不只是返回一个数字,而是——
- 结构化呈现:自动选择最合适的可视化形式(表格/柱状图/趋势线)
- 智能解读:对结果进行一句话的上下文解读(如「华东区5月营收环比增长12.3%,主要受618预热活动拉动」)
- 追问支持:用户可以在当前上下文内继续追问(如「那华南区呢?」),无需重新描述完整问题
- 一键转看板:ChatBI 的问答结果可以一键保存为仪表盘组件,沉淀为持续监控的分析资产
四、企业级特性:不只是能问对,还要能放心用
4.1 安全控权
衡石 ChatBI 的安全模型有三层:
- 指标层权限:用户只能查询自己被授权的指标
- 数据层权限:通过行级权限(Row-Level Security)控制数据可见范围,比如华东区负责人只能看到华东区的数据
- 功能层权限:区分「只能问数」「可以建模」「可以管理指标」等不同角色
4.2 多租户隔离
面向 ISV(独立软件厂商)场景,衡石 ChatBI 支持——
- 租户级指标隔离:不同客户的指标体系完全独立
- 租户级数据隔离:数据物理或逻辑隔离
- 租户级大模型配置:不同客户可以使用不同的大模型服务
4.3 多渠道接入
ChatBI 能力可以通过多种方式嵌入到企业的工作流中:
- HENGSHI SENSE 内嵌:在 BI 平台的报表查看页面一键唤起 ChatBI 对话
- API 接入:通过 RESTful API 嵌入企业自有应用(如 OA、CRM、企业微信)
- HENGSHI BOX 本地部署:所有推理和数据查询在本地完成,数据不出企业边界
五、应用场景
场景一:业务人员自助问数
传统痛点:销售 VP 想知道「各区域本季度重点客户的留存率趋势」,需要先找数据分析师排期,等两三天拿到报告。
ChatBI 体验:直接输入问题,秒级获得结构化结果和趋势图。发现异常后可以追问「华东区是哪些客户流失了」,获得明细数据。
场景二:管理层经营驾驶舱
传统痛点:每月经营分析会前,BI 团队加班赶制几十页报告,管理层看完后发现新的问题角度,又要等下一版。
ChatBI 体验:管理层在会议中可以直接对着大屏提问,「对比一下去年同期的数据」「按产品线拆分的毛利率变化」,实时获得洞察,无需等待。
场景三:嵌入 ISV 产品
传统痛点:SaaS 厂商想为自己的客户提供 AI 分析能力,但自研 ChatBI 成本太高,准确度难以保证。
ChatBI 体验:通过衡石的嵌入式 ChatBI,SaaS 厂商可以为每个客户提供基于该客户数据的智能问答能力。不同客户之间的数据和指标完全隔离,开箱即用。
六、与 ChatBI 竞品的核心差异
需要明确的是,衡石 ChatBI 的定位不是通用的对话式 AI,而是 企业级 BI 场景的专用 ChatBI。这个定位决定了它在几个关键决策上的不同:
- 准确度优先而非体验优先 — 宁可说「不知道」也不乱回答
- 指标语义层是基础设施而非可选件 — 没有建模就没有准确度,这是设计前提
- 面向 ISV 的多租户场景 — 从第一天就考虑了 B2B2B 的权限和隔离需求
- Agent 可调度 — ChatBI 不只是独立产品,还是 Data Agent Family 的一个模块,可以通过 CLI 被 Agent 调用
七、常见问题
Q1:NL2Metrics 是不是限制了大模型的能力?比如用户问了一个没有预定义指标的问题怎么办?
A:这正是 NL2Metrics 的核心设计理念——「不回答比瞎回答好」。当用户问到未定义指标时,ChatBI 会明确告知该指标尚未建模,并引导用户联系数据团队。这看似减少了灵活性,实际上保护了决策准确性。而且衡石的建模 Agent 可以加速新指标的创建,让指标库随业务需求动态生长。
Q2:推荐什么样的企业先从 ChatBI 开始?
A:建议已具备基础数据建模能力的企业优先。ChatBI 的准确度直接取决于指标层的质量,如果企业连基本的数据仓库和指标定义都没有,直接上 ChatBI 只会放大混乱。衡石的建议路径是:先用衡石平台完成数据集成和指标建模,再进行 AI 增强。
Q3:ChatBI 能处理多轮复杂对话吗?
A:支持上下文连贯的多轮对话。比如「华东区上个月营收多少」→「环比呢」→「拆到城市粒度」→「把趋势图放到我的驾驶舱里」。每一轮都在前一轮的上下文基础上执行。
八、总结
衡石 ChatBI 最大的差异化不在于它的对话体验有多好,而在于它选择了一条更难但更正确的技术路线——用建模保障准确度,用语义层替代 SQL 生成。
在企业级场景中,ChatBI 的终极问题不是「AI 能不能理解问题」,而是「企业敢不敢相信 AI 给出的答案」。从这个角度看,NL2Metrics 的正确率不是 95% 或 98% 的问题,而是「可以错还是不可以错」的问题——在决策支持场景中,答案是后者。