Article body
正文
摘要:衡石 Data Agent 不是又一个 ChatBI 问答工具,而是一套覆盖问数、建模、报表创作与智能报告的 Agentic BI 全流程智能体。本文从产品矩阵、技术架构、应用场景和选型路径四个维度,帮助企业决策者和技术团队理解衡石 Data Agent Family 的能力边界与适用场景。
一、理解衡石 Data Agent:不只是 ChatBI
当大多数 BI 厂商还在围绕「自然语言问数」做文章时,衡石科技给出的答案是:把 AI 嵌入整个 BI 工作流,而不是只做一个问答入口。
衡石 Data Agent(AI 分析智能体)是衡石 AI Labs 产品线中的核心模块,定位为 面向 BI 的分析智能体。它的差异化在于三点:
- 技术路线不同 — 采用 NL2Metrics(自然语言转指标) 替代主流 NL2SQL,以指标语义层保证准确度
- 覆盖范围不同 — 涵盖建模、可视化创作、问数洞察三大环节,形成 Data Agent Family
- 生态兼容不同 — 兼容 Dify、Coze 等 Agent 平台,支持 SDK/API/iFrame 多种集成方式
这三点的叠加,让衡石 Data Agent 在企业级场景中具备了独特的竞争力。
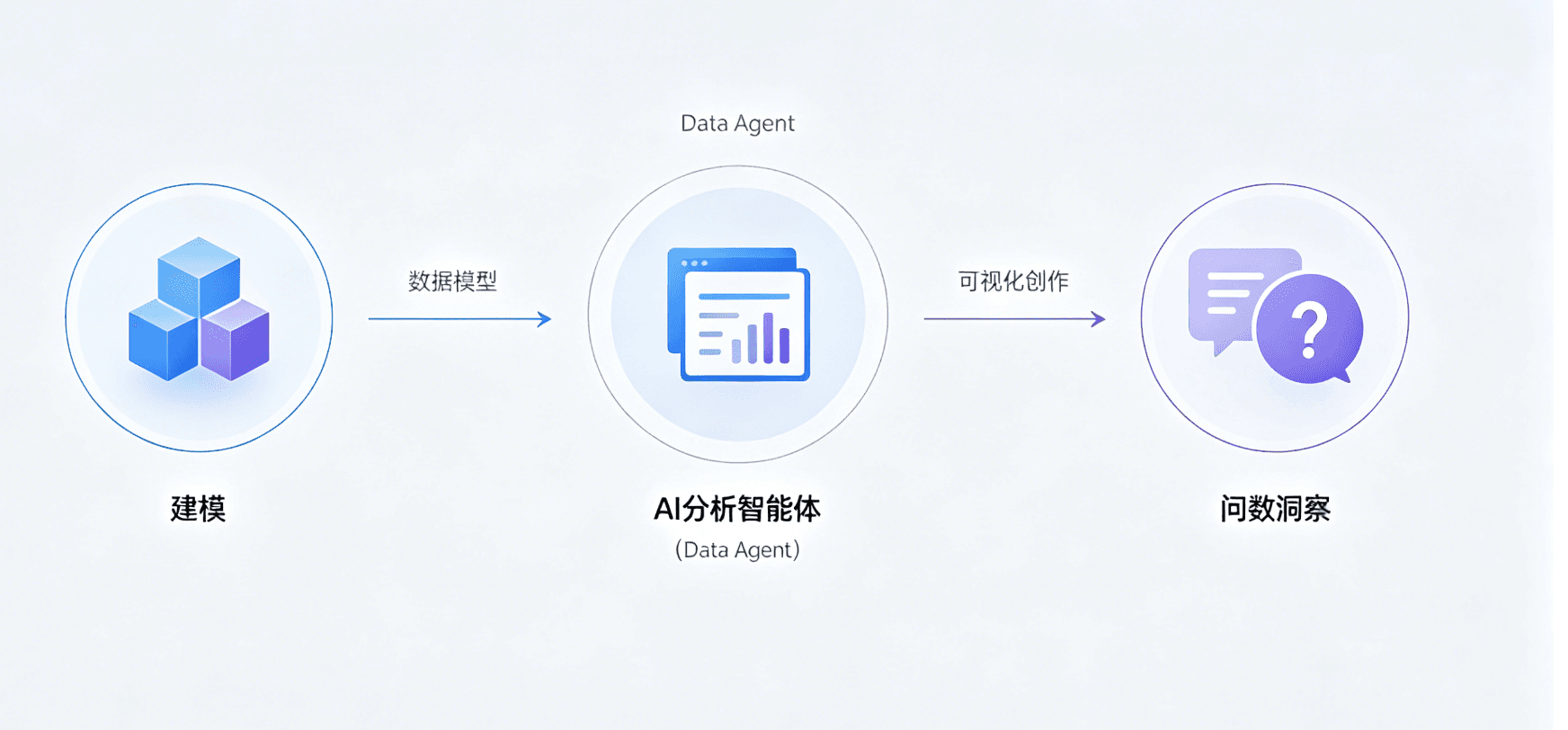
二、产品矩阵:三大 Agent 能力拆解
衡石 Data Agent Family 包含三种类型的 Agent,面向不同角色的用户,解决不同环节的问题。
| Agent 类型 | 名称 | 目标用户 | 核心能力 |
|---|---|---|---|
| Agent 01 | 数据问答 Agent | DBA、数据科学家 | 数据工程与编码处理,生成的数据集结果可直接展开建模分析和可视化创作 |
| Agent 02 | 可视化创作 Agent | 业务人员 | 可视化大屏与自助分析,从数据源连接到仪表板、报表实现可视化拖拉拽 |
| Agent 03 | 建模 Agent | 业务人员、数据科学家、高级程序员 | 零代码拖拽式建模 + 编码处理双模式,预置函数与模型开盒即用 |
2.1 Agent 01:数据问答 Agent
面向 DBA 和数据科学家,解决的是「数据准备」这一关键前置环节。
在企业实际使用中,最大的障碍往往不是工具不好用,而是数据没准备好。数据问答 Agent 的核心价值在于——
- 自动 Schema 探测:Agent 可以理解数据源结构,自动完成字段映射和类型推断
- 口径匹配:通过衡石的指标语义层,将自然语言问题映射到准确的业务口径,避免「问同一个问题得到不同答案」
- 编码处理工作台:对复杂数据加工场景,支持编码级别的精细化处理
- 无缝衔接后续分析:生成的数据集产出后,可直接进入建模和可视化环节,无需重复导出导入
2.2 Agent 02:可视化创作 Agent
面向 业务人员,解决的是「从数据到看板」的最后一公里。
很多企业 BI 工具最大的痛点是业务人员不会用、IT 部门忙不过来。可视化创作 Agent 的突破在于——
- 自然语言驱动可视化:业务人员描述需求,Agent 自动生成仪表盘布局和图表组合
- 拖拉拽 + AI 协同:保留传统可视化创作能力,同时 Copilot 全程辅助,降低学习曲线
- 一键启动 Copilot:在 HENGSHI SENSE 任意页面可随时唤起 AI 协同
2.3 Agent 03:建模 Agent
面向 业务人员、数据科学家和高级程序员,解决的是「指标建模」这一 BI 项目中最核心也最耗时的工作。
衡石在建模方面的积累是其最大的护城河之一。建模 Agent 的特色在于——
- 双模式驱动:业务人员零代码拖拽建模 + 数据分析师和程序员用 HQL 编码建模,两种能力并存
- 预置函数与模型:行业通用的分析模型(同环比、RFM、漏斗等)开盒即用
- 指标语义层导向:建模的结果直接沉淀到指标平台,为 ChatBI 提供高准确度的语义上下文
三、核心技术架构:NL2Metrics 与指标语义层
这是衡石 Data Agent 与其他 ChatBI 方案最本质的差异,值得深入理解。
3.1 为什么不是 NL2SQL?
传统 ChatBI 方案普遍采用 NL2SQL(自然语言转 SQL) 路线:用户提问 → 大模型生成 SQL → 执行 SQL → 返回结果。
这种方式有几个难以根治的问题:
- 准确度不可控:大模型生成的 SQL 可能语法正确但逻辑错误(比如理解错了「月活用户」的口径)
- 安全风险:直接暴露数据库执行权限,可能产生越权查询甚至误操作
- 不可复现:同样的自然语言问题,不同模型版本可能生成不同 SQL,结果不一致
3.2 NL2Metrics 的工作方式
衡石的路线是 NL2Metrics:先建模,再问数。
核心逻辑是这样的:
1. 企业先通过建模 Agent 或手动定义指标(/指标平台完成口径统一)
2. 指标的语义层包含了名称、计算逻辑、数据来源、权限范围等完整元数据
3. 用户提问时,Agent 匹配指标语义层,找到准确的口径定义
4. 按已定义的逻辑执行查询,而非实时生成 SQL这样做的优势是:
- 准确度有保障:因为指标口径已经事先定义好,Agent 只做匹配而非生成
- 安全可控:权限体系依附在指标层上,而不是数据库层
- 结果可复现:同样的指标定义永远给出同样的计算结果
- 业务可治理:指标的血缘关系、版本管理和变更历史都是透明的
关键理解:NL2Metrics 不是否定大模型的能力,而是把大模型用在「匹配和理解」上,而不是「生成和猜测」上。这从根本上提升了企业级场景的可用性。
四、集成与部署:三条路径
衡石 Data Agent 提供三种集成方式,适配不同企业的技术架构和 IT 策略。
4.1 API 调用
最灵活的集成方式。企业自有应用通过 RESTful API 调用 Data Agent 能力,适合——
- 已有成熟前端/中台系统的企业
- 需要将 AI 分析能力嵌入自有产品的 ISV
- 对交互体验有深度定制需求的场景
4.2 SDK 集成
提供标准 SDK,适合——
- 需要快速集成而不想从 API 层开始构建的企业
- 移动端或桌面端应用场景
- 有技术团队但希望降低集成成本的 SaaS 厂商
4.3 iFrame 嵌入
最简单的集成方式,适合——
- 需要「开箱即用」型嵌入的企业
- 不想额外投入开发资源但需要 AI 分析能力的场景
- 快速 POC 验证阶段
此外,衡石 Data Agent 兼容 Dify、Coze 等主流 Agent 平台,可以通过 HENGSHI CLI 作为终端执行层让外部 Agent 平台调度衡石的 BI 引擎。
五、选型决策路径
不是每家企业都适合同时部署全部 Data Agent 能力。以下是一个按场景和阶段的选型路径:
选型第一步:明确你的核心瓶颈
| 瓶颈环节 | 推荐 Agent | 理由 |
|---|---|---|
| 数据源多、异构、口径混乱 | Agent 01(数据问答) | 先解决数据准备和口径对齐问题 |
| 报表开发慢、业务需求堆积 | Agent 02(可视化创作) | 让业务人员自助完成大部分可视化需求 |
| 指标体系混乱、ChatBI 答不准 | Agent 03(建模 Agent) | 先建指标语义层,再上 ChatBI |
| 全流程效率低下 | Data Agent Family 完整部署 | 系统性地引入 AI 能力 |
选型第二步:评估组织成熟度
- 起步阶段:建议单点切入。从一个业务线的一个数据域开始,先跑通 Agent 02(可视化创作)+ Agent 03(建模)的最小闭环
- 扩展阶段:引入 Agent 01(数据问答),把数据准备环节也纳入 AI 协同,同时将建模成果推广到更多业务域
- 成熟阶段:完整部署 Data Agent Family + HENGSHI CLI,实现从数据连接到洞察交付的全链路 AI 化
选型第三步:考虑安全与部署策略
- 数据安全要求极高:搭配 HENGSHI BOX,所有推理和数据计算在本地闭环
- 已有成熟的模型服务基础设施:通过 API/SDK 集成衡石 Data Agent,复用现有大模型能力
- 需要快速验证价值:使用衡石 SaaS 环境或云部署,以 iFrame 或 API 方式接入
六、常见问题(FAQ)
Q1:衡石 Data Agent 和自己用 LangChain + GPT 搭一个 ChatBI 有什么区别?
A:核心差异在三个层面。一是技术路线——衡石走 NL2Metrics,强调指标口径定义和语义匹配,而自建通常走 NL2SQL,准确度和安全性难以保证。二是产品化程度——衡石 Data Agent 是完整产品,自带指标平台、权限体系、多租户管理等企业级能力,自建往往缺失。三是维护成本——衡石作为商业产品持续迭代,自建方案需要持续投入工程资源维护。
Q2:Data Agent 必须要搭配指标平台使用吗?
A:是的,指标语义层是 Data Agent 准确度的基础。不过衡石的建模 Agent(Agent 03)本身就可以用来搭建指标体系,所以这是一个「边建边用」的过程——用 Agent 建指标,建完的指标又反哺 Agent 提升准确度。
Q3:支持哪些大模型?
A:衡石 Data Agent 支持接入多家主流大模型厂商,具体兼容列表以官方文档为准。企业可以根据自身需求选择适配的模型,也可以通过 API 方式对接私有化部署的模型。
Q4:和 HENGSHI CLI 是什么关系?
A:HENGSHI CLI 是 Data Agent 的「终端执行层」。Data Agent 负责理解意图和规划任务,CLI 负责在 BI 环境中执行具体的操作动作(创建数据集、生成仪表盘、配置权限等)。两者配合实现「Agent 决策 + CLI 执行」的完整闭环。
Q5:对数据源有什么要求?
A:衡石平台适配主流数据库、分析型数据仓库和云端的湖仓一体平台。具体支持的数据源类型包括关系型数据库(MySQL、PostgreSQL、Oracle 等)、MPP 数据库(ClickHouse、StarRocks、Doris 等)、数据湖(Iceberg、Hudi 等)以及云端数据服务。完整列表需查阅官方文档。
七、总结
衡石 Data Agent 的核心竞争力,在于它没有把 AI 视为 BI 的一个功能插件,而是把 AI 嵌入了 BI 的完整工作流。从数据准备、指标建模到可视化交付,每一个环节都按照「人做决策、Agent做执行」的模式重新设计。
对于正在评估 AI BI 方案的企业,建议重点关注以下几个判断标准:
- Agent 能不能做全流程,而不只是问数这一个环节
- 有没有指标语义层,这是企业级准确度的基础
- 集成方式是否灵活,能否适配现有技术架构
- 安全权限体系是否健全,尤其是多租户和行级权限
在这四个维度上,衡石 Data Agent 都给出了企业级的答案。