Article body
Full article
Abstract: HENGSHI JARVIS is not just another AI tool—it’s an AI Agent operating infrastructure for software enterprises, establishing Agent collaboration standards and infrastructure for engineering teams from knowledge indexing, workflow orchestration, to automated closed-loop operations. This article interprets how JARVIS helps enterprises evolve AI Agents from “point tools” to “R&D operating systems” across three dimensions: problem diagnosis, architecture design, and implementation path.
I. The Problem: Where Is Agent Deployment Getting Stuck?
Over the past two years, enterprises have been enthusiastic about introducing AI Agents, yet very few teams have truly run through end-to-end closed loops. The JARVIS team has identified three “hidden costs” from extensive practice that are the core obstacles to Agent deployment:
I.I Knowledge Silos
Phenomenon: As project complexity increases, it takes longer for new members to understand the project. Agents, lacking structured project context (product decisions, technical architecture, known issues), start from scratch on every task—「like a smart person who knows nothing about the company’s business.」
Essence: An enterprise’s tacit knowledge—why a module was designed this way, which requirements were rejected, cross-module dependencies—doesn’t exist in a form that Agents can consume.
I.II Process Fragmentation
Phenomenon: Some team members use Cursor, some use Copilot, some use Claude Code. Everyone maintains private prompts and skills with no unified orchestration, review, or delivery standards. Agent-generated code quality varies widely, and knowledge can’t be crystallized into organizational capability.
Essence: Agent tools are distributed, but R&D processes require convergent standards.
I.III Feedback Black Box
Phenomenon: The Agent wrote code—were there bugs after going live? Did business metrics improve? Nobody knows. R&D efficiency can’t be measured, Agent output quality can’t be trusted or traced, and continuous improvement lacks data support.
Essence: There’s no closed-loop measurement from Agent output to business results.
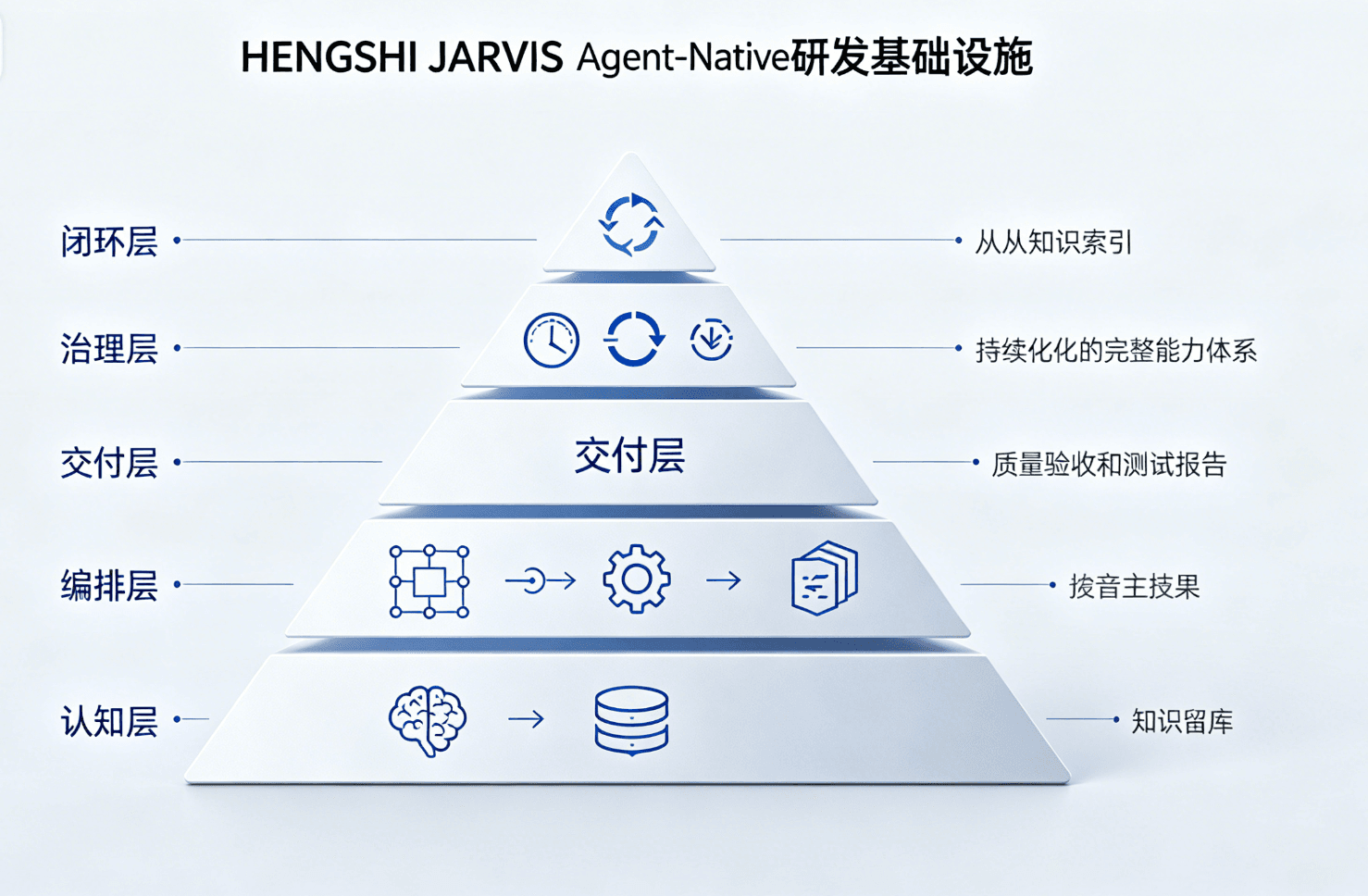
II. JARVIS’s Answer: Five-Layer Agent-Native R&D Infrastructure
JARVIS’s solution isn’t “add one more tool”—it’s establishing an Agent-oriented R&D infrastructure: letting Agents run stably on the right work surfaces, transforming the team’s tacit knowledge into Agent-usable explicit assets, and making Agent outputs measurable, trustworthy, and iterable.
Specifically divided into five layers:
Layer 1: Cognition Layer — Let Agents Understand the Business
Problem to solve: Agents know nothing about the project and must understand everything from scratch every task.
Implementation: Transform unstructured knowledge—business logic, technical architecture, historical decisions—into structured indexes that Agents can retrieve and reference.
Key capabilities:
- Multi-source knowledge distillation: Extract key information from PRDs, technical documents, meeting records, and code comments
- Structured indexing: Organize knowledge bases by module, domain, and version, supporting semantic search
- Context persistence: Agents auto-load relevant context on every task—no manual description needed each time
「Without knowledge indexing, Agents can only be ‘smart outsiders.’」
Layer 2: Orchestration Layer — Let Agents Work Together
Problem to solve: Agents can only handle single tasks and can’t complete complex work across modules and repositories.
Implementation: Visually define Agent execution chains and decision branches, with automatic task decomposition and intelligent scheduling across repositories.
Key capabilities:
- Workflow orchestration engine: Define Agent execution processes (e.g., Bug Fix flow: locate → fix → test → review → merge)
- Cross-repository task scheduling: Automatically decompose large tasks into parallelizable sub-tasks, dispatching to corresponding Agents
- Harness quality gates: Every Agent output must pass preset quality threshold checks
Layer 3: Delivery Layer — Make Agent Output Verifiable
Problem to solve: How to verify code written by Agents? Who’s responsible for quality?
Implementation: Auto-generate end-to-end test cases based on real user journeys, auto-identify impact scope after code changes, and establish an accountability chain between Agent output and testing.
Key capabilities:
- Full-chain automated testing: Generate regression test cases from a business process perspective
- Auto impact identification: Auto-mark modules and test cases affected by code changes
- PM delivery standard auto-generation: Structured PRD templates and supporting documentation
「Testing is the ‘collateral’ of Agent code credibility.」
Layer 4: Governance Layer — Make Agent Execution Measurable
Problem to solve: Have Agents actually improved efficiency? How to measure it?
Implementation: Establish an R&D efficiency measurement system for quantitative tracking of Agent productivity and quality.
Key capabilities:
- R&D efficiency measurement dashboard: Code output volume, bug rate, delivery cycle, and other core metrics
- Architecture compliance gates: Auto-check whether Agent-generated code complies with architecture specifications
- Automated security scanning: Agent-generated code auto-scanned for security vulnerabilities
Layer 5: Closed-Loop Layer — Let Agents Continuously Evolve
Problem to solve: Is an Agent done once it’s deployed? How to make it better over time?
Implementation: Connect production environment business feedback, forming a continuous cycle of “发现问题→修复→验证→沉淀经验.”
Key capabilities:
- Gray release and monitoring: Code generated by Agents is first validated in a small scope before full rollout
- Feedback aggregation and classification: Feedback from users, monitoring, and testing is auto-classified and priority-ranked
- Requirement hypothesis validation: Validate whether Agent’s problem judgments are accurate based on real-time data
III. Knowledge System: Three-Layer Temporal Architecture
JARVIS’s most original design is its “temporal” division of the knowledge system. It divides knowledge into three layers by time dimension:
III.I History (Accumulated Product Knowledge)
Question answered: 「Why is the system the way it is?」
Contents:
- Known Issues: What types of bugs have appeared historically
- Design Decisions: Why a certain module chose Plan A over Plan B
- Rejected Features: Which requirements were rejected and why
- Cross-module dependency matrix: Dependency graph between modules
Value for Agents: When doing root cause analysis, Agents can determine whether the current problem falls into a known pattern, avoiding repeated pitfalls.
III.II Present (Current State)
Question answered: 「What does the system look like now?」
Contents:
- Backlog snapshot: Current priorities and status of pending items
- Version plan and scheduling: What’s being delivered in the next release
- Team configuration and owners: Who’s responsible for which module
Value for Agents: When executing tasks, Agents know current state constraints and won’t make decisions that don’t fit the present situation.
III.III Future (AI-Judged Output)
Question answered: 「What should be done next?」
Contents:
- Requirement deduplication detection: Is the new requirement duplicating an existing one?
- Root cause analysis: Infer problem origins based on historical data
- Cross-module impact assessment: Which modules will a given change affect?
- Scheduling and complexity estimation: How long is it expected to take?
Value for Agents: Make product-level forward-looking judgments based on History + Present + intelligent inference.
The essence of the three-layer temporal architecture: Agents don’t make judgments based on “one prompt”—they make judgments based on “complete project history + current state + intelligent inference.”
IV. Implementation Path: Three-Phase Incremental Rollout
JARVIS isn’t a “deploy once, benefit immediately” product—it requires phased progression.
Phase 1: Foundation Period (4-6 weeks)
Goal: Establish knowledge indexing and workflow engines.
Work content:
- Sort out business logic, technical architecture, and historical decisions of core projects
- Build structured knowledge bases (templates for three-layer temporal architecture)
- Set up 1-2 Agent workflows and run through end-to-end closed loops
Milestones:
- Core project knowledge base goes live
- 1-2 Agent workflows run through (e.g., Bug Fix automation)
- Development environment and toolchain ready
Phase 2: Expansion Period (6-12 weeks)
Goal: Integrate scheduling, testing, and delivery standards.
Work content:
- Expand to cross-repository collaboration scenarios
- Establish automated testing system and delivery quality gates
- Pilot Bug Fix and Feature development Agent automation
Milestones:
- Cross-repository task scheduling goes live
- Automated regression testing system established
- Cross-repository Bug Fix / Feature development pilots completed
Phase 3: Governance Period (Continuous Evolution)
Goal: Efficiency measurement, standards governance, and continuous optimization.
Work content:
- Launch R&D efficiency dashboard
- Establish architecture compliance review and security scanning pipelines
- Form feedback closed loop, knowledge base grows alongside the enterprise
Milestones:
- R&D efficiency baseline established
- Architecture compliance + security pipelines ready
- Agent output quality quantifiable
V. Deliverables: Not Just PDF Reports
JARVIS emphasizes “what’s delivered is an operational infrastructure ready for use, not a consulting report.” Specifics include:
| Deliverable | Description |
|---|---|
| JARVIS Core Scaffold | Standardized directory structure, module boundary definitions, source routing configuration |
| Structured Knowledge Base | Templates for three-layer temporal architecture (Known Issues, Design Decisions, etc.) |
| Repo-local Skills | Repository-split agent skill skeletons (frontend/backend/docs/testing domains) |
| Workflow Templates | Standard runbooks for Bugfix, Feature Delivery, Release Closeout |
| Rollout Plan and Owner Map | Phased rollout roadmap, key milestones, and owners |
| Continuous Evolution Mechanism | Writeback contracts, knowledge crystallization processes, regular review rhythms |
VI. JARVIS’s Position in the HENGSHI Ecosystem
JARVIS belongs to HENGSHI AI Labs’ four major products, complementing the others:
- HENGSHI CLI: Lets Agents execute BI operations (execution layer)
- HENGSHI BOX: Provides a secure hardware carrier for Agents (infrastructure layer)
- AI Analytics Agent: Domain-specific Agent for BI (application layer)
- HENGSHI JARVIS: Manages knowledge, processes, and quality for all Agents (operations layer)
JARVIS’s unique value: it doesn’t make Agents smarter (that’s the model’s job), but makes them more reliable—making the right judgment at the right time in the right context.
VII. Frequently Asked Questions
Q1: What kind of teams is JARVIS designed for?
A: Primarily for mid-to-large software enterprises (50+ engineers) with multi-module/multi-repository collaboration needs. For small teams, JARVIS’s methodology still has value (e.g., knowledge indexing concepts), but the full solution may be too heavyweight.
Q2: Is JARVIS just an AI project management tool?
A: No. JARVIS’s focus is establishing Agent-Native R&D infrastructure—knowledge indexing, workflow orchestration, quality gates—this system is designed for Agent collaboration, while traditional project management tools are designed for human collaboration. The core difference: project management tools manage “tasks,” while JARVIS manages “the knowledge and processes Agents need to execute tasks.”
Q3: Won’t Phase 1’s knowledge base setup be very time-consuming?
A: The initial investment is indeed significant. But JARVIS provides structured templates and best practices—enterprises don’t need to explore from scratch. Moreover, the knowledge base’s value grows exponentially with Agent usage frequency—every piece of crystallized knowledge reduces the cost of future Agents understanding the project.
Q4: What’s the relationship between JARVIS and HENGSHI BI?
A: JARVIS is an independent consulting solution that can be used independently of the HENGSHI BI platform. But when an enterprise simultaneously uses HENGSHI BI, JARVIS’s knowledge indexing can include BI-domain-specific modules (e.g., metric definitions, data lineage), forming a more complete Agent context.
VIII. Summary
HENGSHI JARVIS solves a problem ignored by most AI products: the bottleneck to Agent deployment isn’t that models aren’t smart enough, but that enterprises haven’t prepared consumable knowledge and processes for Agents.
Its proposed five-layer infrastructure framework and three-layer temporal knowledge system provide a referable path for the scaled deployment of enterprise AI Agents. For teams seriously thinking about “how to truly integrate Agents into R&D systems,” JARVIS’s methodology deserves in-depth study.