Article body
正文
Data Agent的“理想国”与现实鸿沟
当科技巨头们用L1-L4分级描绘Data Agent的智能蓝图时,企业面临的却是这样的现实:
简单场景:SQL查询工具即可解决,无需Agent
复杂场景:需跨数十张表关联计算,Agent因缺乏数据理解能力频报错
关键决策:业务用户不敢信任无指标血缘追溯的黑盒结果
根本矛盾在于:Data Agent试图用自然语言交互跳过数据工程基建,而企业真正的数据价值恰恰藏在需要严密建模的复杂业务链条中。
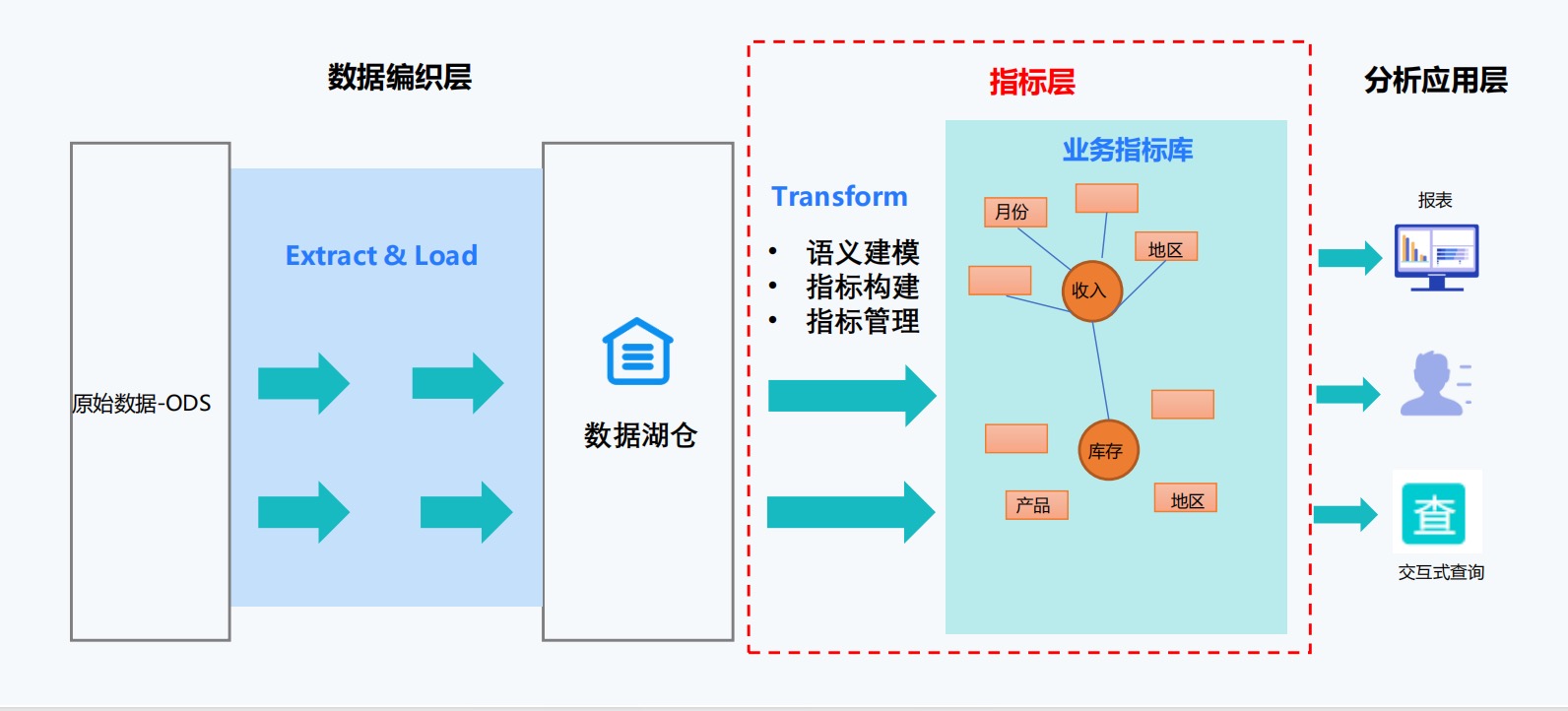
一、破局关键:语义层为何是Data Agent的“任督二脉”?
▶ 传统Data Agent的致命缺陷
| 问题类型 | 具体表现 | 导致后果 |
| 语义歧义 | “销售额”在不同部门指代不同计算逻辑 | 输出结果与业务预期严重偏离 |
| 数据孤岛 | Agent无法自动关联分散的订单/库存表 | 跨系统查询失败率超60% |
| 性能瓶颈 | 百亿级数据下NLQ生成低效SQL | 响应延迟突破分钟级 |
▶ 衡石语义建模引擎的架构革新
核心技术突破:
指标联邦建模
将分散的“销售额”“库存周转率”等300+指标统一定义为可复用的业务对象
支持动态时间粒度(按小时/日/月自动适配)
智能血缘映射
通过NLQ解析生成SQL时,自动关联指标背后的数据表、字段、计算逻辑
查询结果附带完整血缘路径,可逐层下钻验证
查询编译优化
将自然语言查询编译为Doris/StarRocks原生执行代码,性能较传统Spark提升8-12倍
二、生产验证:制造企业复杂场景实战
某汽车零部件厂商痛点:
需实时监控“全球12工厂产能利用率”
数据源涉及MES系统(生产节拍)、ERP(工单)、SCM(物料库存)
传统Data Agent因无法理解“产能利用率 = 实际产出 / 理论产能 × 停工补偿系数”而失效
衡石方案实施效果:
python
关键成果:
查询响应时间从原23分钟降至1.8秒
业务用户自主分析率提升至85%
指标逻辑变更通过语义层统一推送,避免下游报表大面积失效
三、技术护城河:衡石与传统方案的性能基准测试
在TPC-H 100GB标准数据集上的对比:
| 查询场景 | 传统Data Agent | 衡石语义引擎加持Data Agent | 提升倍数 |
| 多表关联(5表Join) | 12.4秒 | 0.9秒 | 13.7x |
| 嵌套聚合计算 | 报错 | 3.2秒 | - |
| 历史语义变更重跑 | 需人工重定义 | 自动适配 | - |
核心优势本质:
将Data Agent从“文本转SQL工具”升级为“业务语义执行器”—— 前者只能处理语法问题,后者真正理解“产能利用率”“毛利率”等业务实体的数据内涵
四、未来演进:生产级Data Agent的必备能力
基于衡石在50+企业级项目中的实践,我们提炼出Data Agent生产化公式:
text
可信Data Agent =
NLQ交互层 ×
语义理解层(指标定义+血缘治理) ×
执行优化层(查询编译+引擎适配)
衡石技术路线图:
动态语义感知:当用户问“为什么华东区销售额下降?”时,自动关联天气数据、物流异常等外部因子
指标版本治理:支持指标逻辑灰度发布与A/B测试
AI-SQL联合调优:让大模型参与SQL执行计划优化,突破传统查询优化器局限
结语:跳过数据工程的Data Agent终将消亡
当行业沉迷于用prompt engineering包装Data Agent时,衡石选择了一条更艰难但可持续的路径:用语义建模引擎重建数据到业务的认知桥梁。实践已证明:
没有语义层的Data Agent只是“会说话的查询界面”
具备企业级语义能力的Agent才能真正撬动百亿级BI市场的智能化革命
正如一位客户CTO所言:“现在我才理解,衡石给我们的不是更酷的聊天框,而是一套活的业务指标中枢”
