Article body
正文
在数据驱动的决策体系中,没有什么比“数据口径不一”更具破坏性。当市场部报告的“活跃用户”与产品部定义的相差20%,当财务计算的“毛利率”与销售团队的理解大相径庭时,企业不仅陷入无休止的内耗与争论,更可能基于错误的事实制定出灾难性的战略。指标的不一致性,如同在建筑的基石中埋下了裂痕,随时可能导致整个数据大厦的倾覆。
解决这一痛点的理想方案,在业界已被倡导多年:“一处定义,处处可用”。这个理念似简单,背后却是对企业数据架构、工作流程和技术能力的极致考验。衡石科技的指标平台,正是为实现这一愿景而构建的精密系统。本文将深入技术内核,探秘衡石平台如何通过一套严谨的保障机制,将这一理念变为现实。
一、 “一处定义,处处可用”的技术挑战
在深入衡石平台的解决方案之前,我们首先需要理解实现这一目标所面临的三大技术挑战:
定义孤岛:不同部门的分析师使用各自的工具(如Excel、本地BI文件)定义指标,缺乏一个统一的、受版本控制的中心化仓库。
逻辑散落:指标的计算逻辑(如SQL代码)分散在无数的报表、查询脚本和应用程序中。当业务规则变化时(如“退货订单是否计入销售额?”),修改和维护成本极高,且极易遗漏。
上下文缺失:一个指标被呈现时,其背后的过滤条件、时间范围、所属维度等上下文信息可能丢失或被误解,导致同样的指标在不同场景下得出不同结果。
传统的解决方案,如依赖严格的文档管理或人工审核,不仅效率低下,且无法从根本上解决实时性和一致性问题。衡石指标平台的选择是——通过平台化的技术手段,进行强制性的约束与智能化的赋能。
二、 衡石指标一致性保障的核心机制
衡石平台通过一个环环相扣的技术体系来保障指标的一致性,其核心可以概括为四大机制。
机制一:中心化的指标定义与元数据管理
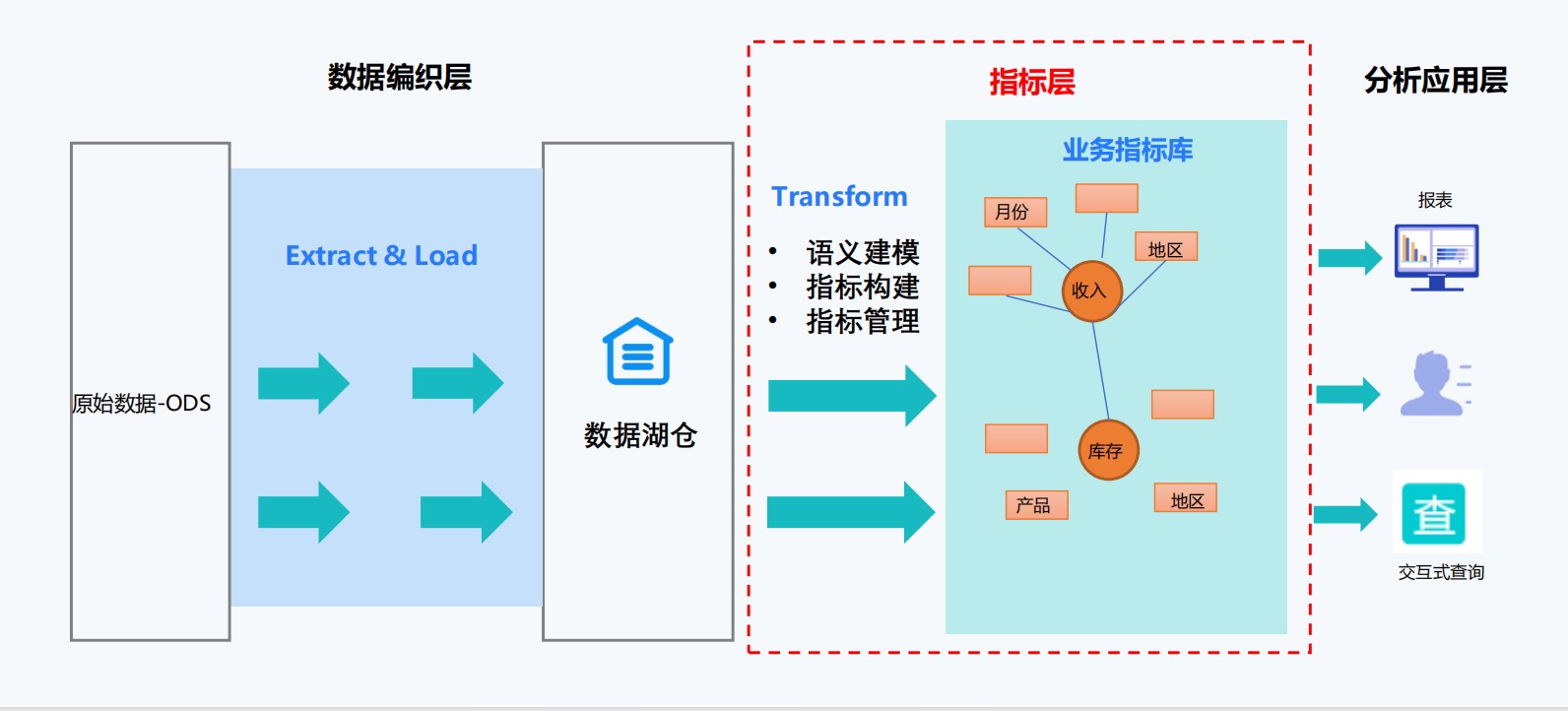
这是实现“一处定义”的物理基础。衡石平台内置了一个统一的指标中心,作为整个企业所有核心指标的“唯一真相源”。
标准化定义界面:在这里,数据工程师或分析师可以使用声明式的方式,而非纯代码方式,来定义一个指标。平台提供了丰富的配置项:
基础信息:指标名称、业务描述、负责人。
数据模型关联:明确指标来源于哪个已治理好的逻辑数据模型或物理表。
计算表达式:基于已定义的基础字段,通过图形化或类SQL的表达式语言来定义计算逻辑(如
SUM(销售金额) / COUNT(DISTINCT 客户ID))。过滤条件:永久性的过滤条件(如只计算“状态为‘已完成’的订单”)。
聚合粒度:明确指标可被聚合的维度(如按时间、地区、产品类别等)。
版本控制与审计:所有指标的定义、修改历史都被平台记录和版本化。谁、在什么时候、修改了什么内容一目了然,确保了定义过程的可靠性与可追溯性。
机制二:强大的逻辑数据模型与语义层
指标必须构建在干净、统一的数据基础之上。衡石平台的逻辑数据模型 和语义层是支撑指标可用的关键。
逻辑数据模型抽象:平台允许数据团队将复杂的物理表(如多张关联的数据库表)封装成业务友好的逻辑视图。例如,将一个复杂的多表JOIN封装成一个简单的“销售事实表”,其中包含清洗好的“销售金额”、“产品ID”、“客户ID”等字段。
语义层翻译:这是让业务人员理解数据的关键。平台将逻辑数据模型中的技术字段名(如
amt)映射为业务术语(如“销售额”),将表之间的关联关系可视化。当业务人员在定义指标或拖拽分析时,他们操作的是“产品”、“客户”这些业务概念,而非晦涩的表名和列名。这确保了指标定义时所引用的基础元素是唯一且明确的。
机制三:统一的查询引擎与AST优化
这是实现“处处可用”的执行保障。当业务人员在报表、仪表盘或自助分析界面中使用一个已定义好的指标时,衡石平台的统一查询引擎开始工作。
抽象语法树解析:用户的每一次拖拽操作,都会被平台翻译成一个结构化的查询请求,并生成一棵抽象语法树。这棵AST中包含了要查询的指标、维度、过滤条件等信息。
指标逻辑下推:查询引擎在解析AST时,会识别出其中包含的已定义指标。然后,引擎会从“指标中心”获取该指标的最新计算逻辑,并将其“下推”并合并到整个查询的AST中。
SQL生成与执行:最终,引擎会将这棵合并后的、完整的AST编译成优化过的、针对底层数据源(如OLAP数据库、数据仓库)的SQL语句。关键在于,指标的计算逻辑是在查询时,由引擎统一生成并执行的,而非预先计算好一个静态的值。 这就保证了无论这个指标在何处、被何人、以何种方式使用,其底层执行的计算逻辑永远是一致的。
一个技术示例:
假设定义了指标 毛利率,其逻辑为 (SUM(销售额) - SUM(成本额)) / SUM(销售额)。
场景A:用户拖拽
毛利率和产品类别到报表中。场景B:用户拖拽
毛利率和年月到另一个仪表盘,并过滤了地区 = ‘华东’。
在这两个场景中,衡石查询引擎生成的SQL会分别是:
场景A SQL:
sql
SELECT 产品类别, (SUM(销售额) - SUM(成本额)) / SUM(销售额) AS 毛利率 FROM 逻辑销售模型 GROUP BY 产品类别;
场景B SQL:
sql
SELECT 年月, (SUM(销售额) - SUM(成本额)) / SUM(销售额) AS 毛利率 FROM 逻辑销售模型 WHERE 地区 = '华东'GROUP BY 年月;
可以看到,毛利率的核心计算逻辑被严格保持一致,并由引擎动态注入到不同上下文的查询中。
机制四:全方位的权限与上下文继承
为了确保指标在“处处可用”时不会出现数据安全和上下文错误,平台设计了精细的权限和上下文继承机制。
行级权限控制:当不同部门的用户查看同一个“销售额”指标时,平台会根据用户的身份(如所属部门、角色),自动在查询的WHERE条件中注入相应的数据权限过滤器。例如,A区经理只能看到A区的数据。这保证了下游应用在“可用”指标时,看到的是自己权限范围内的、正确切片的数据。
上下文继承:指标在定义时,其所属的业务域、关联的维度等信息已被记录。当业务人员使用该指标时,平台会自动建议与之相关的维度,避免出现“用产品颜色维度去分析门店数量指标”这类不匹配的逻辑错误。
三、 带来的核心价值
通过以上四大机制,衡石指标平台为企业带来了颠覆性的价值:
决策可信度提升:公司上下基于同一套“事实”进行决策,消除了内耗,提升了战略执行效率。
运维效率飞跃:业务规则变更时,只需在“指标中心”修改一次定义,所有下游报表和仪表盘即自动更新,维护成本呈数量级下降。
赋能业务与解放数据团队:业务人员可以放心、自主地使用被严格定义的指标进行探索,而数据团队则从无尽的“取数、核对、修改报表”的循环中解放出来,专注于更高价值的数据架构与治理工作。
结语
“一处定义,处处可用”不再是一个理想化的口号。衡石指标平台通过其中心化的定义仓库、稳健的逻辑模型、智能的查询引擎以及精细的权限控制,构建了一套完整、自洽的技术闭环,将指标一致性从一种管理规范,转变为一种由平台强制保障的技术特性。
这背后体现的,是衡石科技对现代企业数据栈的深刻理解:只有将正确的数据治理理念,沉淀为平台的核心技术能力,才能规模化地赋能组织,最终构建起真正数据驱动的智慧企业。 当指标的一致性得到根除,数据才能真正成为企业最坚实的资产,而非负担。
